

Introduction
EventStoreDB (ESDB) is a log stream database oriented to architectures based on event-sourcing. The data in EventStoreDB is stored into streams, and each stream contains a log of events. For this reason, ESDB is a very suitable candidate for working with event-sourcing architectures and it allows us to easily implement the CQRS pattern, where there are projections that transform the events produced by the commands into data that can be consumed by the queries.
In EventStoreDB, there are three types of nodes: Leader, Follower and ReadOnly. The Leader node is the node where we write or read data and there can be only one Leader in the cluster. Follower nodes replicate the changes from the Leader node and they are not directly used for writing or reading data. However, if the Leader node is down, one Follower can be re-elected as the new Leader. For high-availability, it is recommended to have at least three nodes in three different availability zones (one leader and two followers). Finally, ReadOnly nodes are a special type of node that we can only use for reading data. This node will replicate the changes from the Leader. ReadOnly nodes cannot be Leaders or Followers, so they won’t participate in re-elections.
When we are using event-sourcing, we will normally be managing many projections, so if we are using one or more ReadOnly nodes, our projections read from them and would prevent overloading the reader node. However, there are limitations and adding ReadOnly nodes dynamically (scaling-out) might not be a good idea for multiple reasons:
- As we add more nodes, they will be replicating the data from the Leader node, so that will put more pressure on the leader node.
- Even if we add more nodes to a cluster, the existing projections won’t use them, as they already have their connections established with a particular node.
For this reason, when it comes to provisioning EventStoreDB, planning in advance the demand we are going to need and scale up/down the cluster is a more suitable approach.
In this article, we are going to see how we can scale up/down EventStoreDB without downtime leveraging the cluster capabilities. I’m going to focus on scaling up/down, but this approach can also be used for applying changes that require downtime, such as upgrading the SO, the version of ESDB, etc.
Scaling up/down EventStoreDB
In order to run EventStoreDB, we are using AWS EC2. In EC2, if we want to change the type of instance, we have to stop the instance, change the instance type and start the instance. In addition, once the instance has stated, the node will have to catch up. We can keep checking the endpoint /health/live, and when it returns 204, the node has caught up.
It is not a complex process, but if we apply it for a running instance, it will require downtime. However, if we are using a cluster, we can leverage this to scale up/down the cluster without downtime.
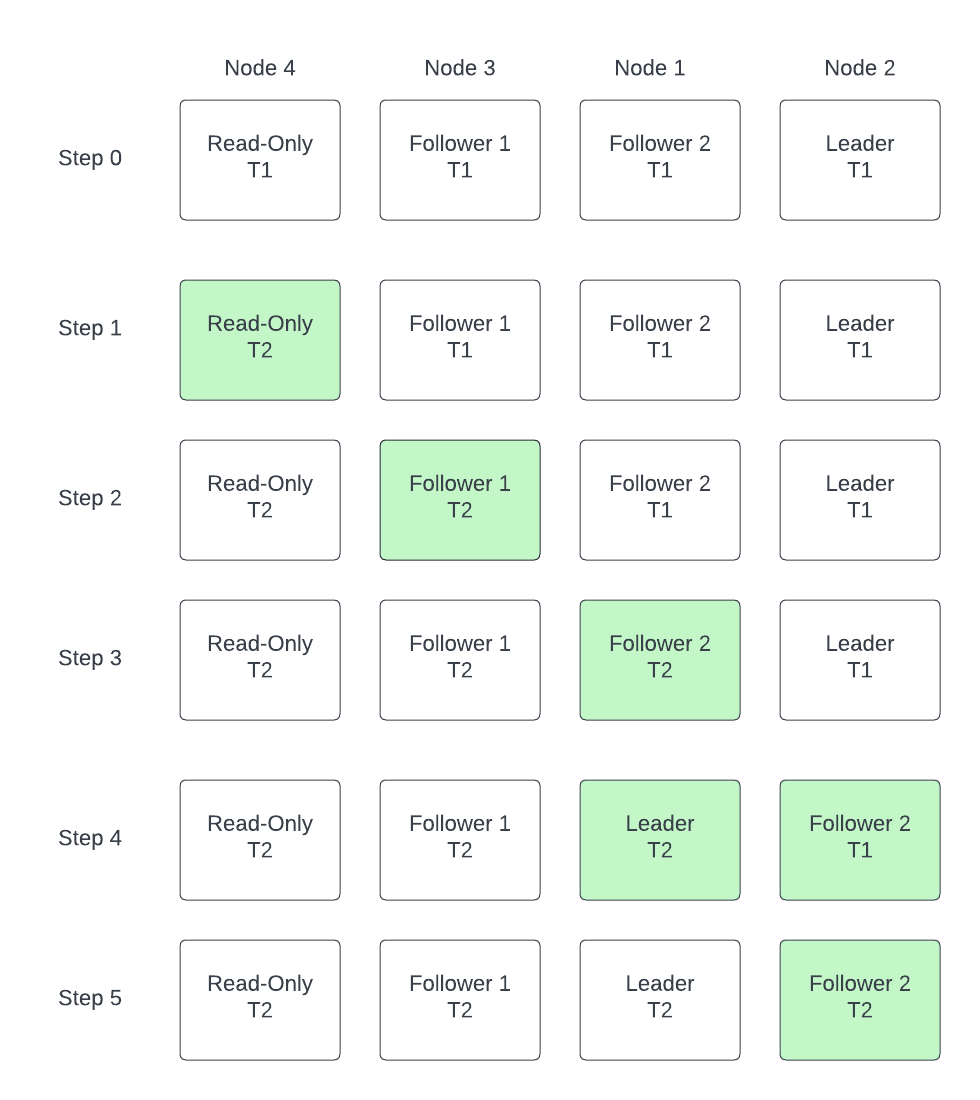
In order to do so, we will update first the ReadOnly nodes, as they can be removed from the cluster and the consumers will automatically start reading from the Leader node. Then we will update the instance type for the Follower nodes. Since nobody is reading/writing in this nodes, we can turning them off without affecting any consumers, but it is recommended to do it sequentically, so we allways have at least two nodes running. Finally, we will update the Master node. However, after doing this, we will reduce the priority of this node and force a re-election, so this node will be a Follower when we turn it off. As a result, it won’t affect any producers or consumers.
This process is described in the following diagram, where we have a cluster with four nodes, 1 Leader, 2 Followers and 1 ReadOnly, and we want to update the instance time from T1 to T2:
Architecture and implementation
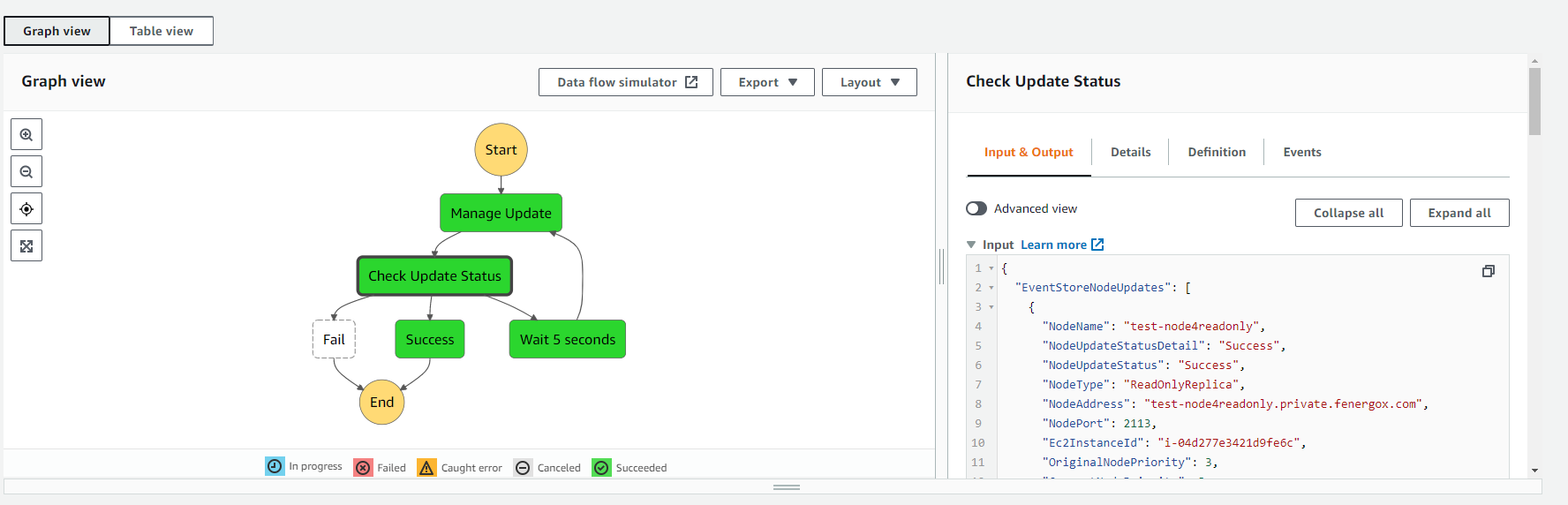
For the implementation, we have a lambda which implements a finite-state machine. The current status of the update is stored in a JSON object. This object is sent to the lambda as input. On the other hand, the lambda returns the same object as output, with the corresponding updates. In this way, we can track the status of the update and how it is making progress across every iteration. The lambda will be invoked by a step function every 5 seconds. Then, the step function will manage the long-running process, so the lambda execution time is short. This is more cost effective and prevents timeouts in the lambda, as updating all the nodes of the cluster can take some time.
The step function will also tack the outcome of the process, so it can finish the step function as success or failure.
This is the graph view for the step function:
For the initial input of the step function, we just need to configure the type of update (as this approach can be used for other type of updates) and the instance type:
1
2
3
4
{
"UpdateStrategy": "Ec2InstanceTypeUpdate",
"TargetInstanceType": "t2.xlarge"
}
Then, for every iteraction, we will have an output what will show us how the process is making progress. For example, in the following output, we see that nodes test-node4readonly and test-node3 were already successfully updated, node test-node is in progress and the node test-node2 is pending. We can also see the number of iterations for each node. In addition, we have a parameter MaxNumberOfIterationsPerNodeUpdate that will allow us to timeout the update if any node updates exceed that threshold.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
{
"EventStoreNodeUpdates": [
{
"NodeName": "test-node4readonly",
"NodeUpdateStatusDetail": "Success",
"NodeUpdateStatus": "Success",
"NodeType": "ReadOnlyReplica",
"NodeAddress": "test-node4readonly.example.com",
"NodePort": 2113,
"Ec2InstanceId": "i-04d277e342129fe6c",
"OriginalNodePriority": 3,
"CurrentNodePriority": 3,
"UpdateIterations": 19
},
{
"NodeName": "test-node3",
"NodeUpdateStatusDetail": "Success",
"NodeUpdateStatus": "Success",
"NodeType": "Follower",
"NodeAddress": "test-node3.example.com",
"NodePort": 2113,
"Ec2InstanceId": "i-03191b6f020b34580",
"OriginalNodePriority": 2,
"CurrentNodePriority": 2,
"UpdateIterations": 18
},
{
"NodeName": "test-node",
"NodeUpdateStatusDetail": "CaughtUp",
"NodeUpdateStatus": "InProgress",
"NodeType": "Follower",
"NodeAddress": "test-node.example.com",
"NodePort": 2113,
"Ec2InstanceId": "i-017bbfe8345fcf55e",
"OriginalNodePriority": 0,
"CurrentNodePriority": 0,
"UpdateIterations": 5
},
{
"NodeName": "test-node2",
"NodeUpdateStatusDetail": "Pending",
"NodeUpdateStatus": "Pending",
"NodeType": "Leader",
"NodeAddress": "test-node2.example.com",
"NodePort": 2113,
"Ec2InstanceId": "i-061d6f4c1fj38f17",
"OriginalNodePriority": 4,
"CurrentNodePriority": 4,
"UpdateIterations": 0
}
],
"ClusterUpdateStatus": "InProgress",
"UpdateStrategy": "Ec2InstanceTypeUpdate",
"TargetInstanceType": "t2.xlarge",
"MaxNumberOfIterationsPerNodeUpdate": 1000
}
We could also implement the finite-state machine as part of the step function, but having the logic in the lambda gives us some benefits:
- It is easy to maintain, test and extend.
- It simplifies the approach. To implement that process with one lambda per step, we would’ve needed more than 10 lambda functions.
- It is not coupled to step-functions. We could run the same process from any source, for example as an SSM automation.
- It gives us flexibility, since we can customize the current state and the lambda will continue the process. This can be handy if something goes wrong in the middle of the process and we want to resume it from the last valid state.
Workflow and extensibility
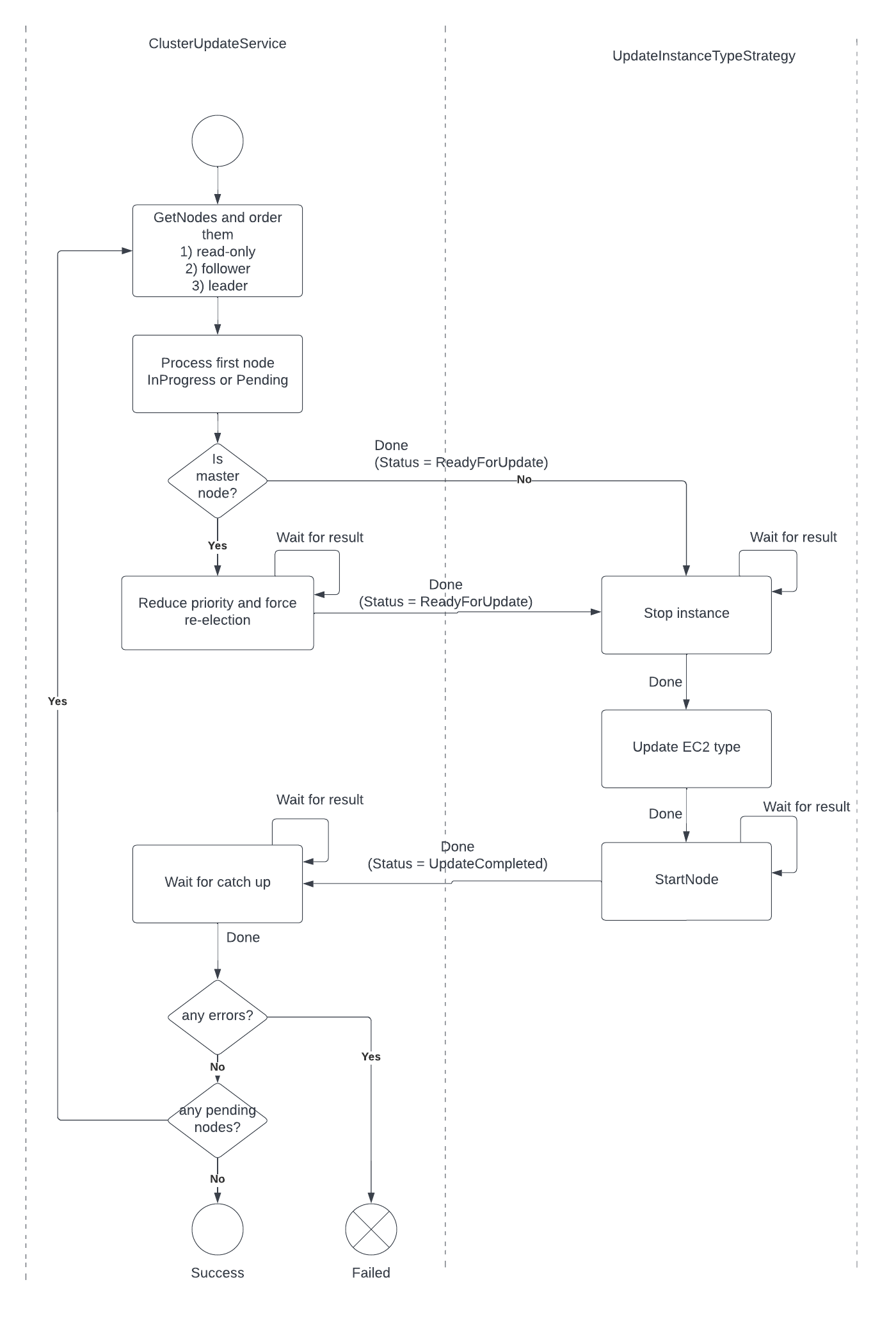
In order to perform the update of the cluster, we have implemented an strategy pattern, so we can implement multiple types of updates for EventStore cluster. Then, we have two main classes: the class ClusterUpdateService that orchestrates the update across the nodes of the cluster, and the class UpdateInstanceTypeStrategy that implements how we update the type of an EC2 instance.
If we observe the workflow, we can see that the process starts by ordering the nodes of the cluster, so we first process the read-only nodes, then the follower and finally the leader node. In order to get the information from the nodes, we will use the /gossip endpoint, and we will also check this endpoint for every iteration, in case the role of any node had changed.
To decide which is the current processing node we select the first node with NodeUpdateStatus equals to InProgress or Pending.
If the current node is a Leader node, we need to reduce its priority and force a re-election until the node has the role of Follower. You can find more information about the leader resignation process in this link.
Once our node it is ready to be updated, we stop the EC2 instance, change the instance type and start the EC2 instance again.
After doing that, we have to check if the node caught up, so we can start processing the following node or finish the process if there are no more pending nodes.
If there were any failures during the update, the process will stop and the step function will finish as failed.
Conclusions
In this article we have seen how an EventStoreDB cluster works and how we can leverage this to perform updates to the cluster progressively, so we prevent having downtime.
It has also be proposed an implementation that uses AWS serverless services, providing a solution based on AWS lambda and AWS step functions. For now solution is being used to update the EC2 instance type, but it can be easily extended for other types of updates, as it implements an strategy pattern.
This process can be triggered manually based on some metrics that we are actively monitoring or we could also configure AWS CloudWatch alarms that trigger the step function automatically via EventBridge.