
Introduction to Event Sourcing and CQRS
The fundamental idea of Event Sourcing is ensuring that every change to the state of an application is captured in an event object, and that these event objects are themselves stored in the sequence they were applied for the same lifetime as the application state itself. (For more information about Event Sourcing I recommend this post written by Martin Fowler).
Based on my experience working with Event Sourcing, having the sequence of events allows you to perform awesome functionalities, like time travelling or replaying your events into multiple storage technologies. However, it can be tricky for some scenarios. To explain this better, I need to introduce Event Sourcing working together with Command Query Responsibility Segregation (CQRS). If you are not familiar with CQRS, the idea behind it is splitting commands (write operations) from queries (read operations), so they can work independently. (more info about CQRS in this post).
CQRS and EventSourcing in practice it is illustrated by the subsequent diagram, where we are using EventStore as Event Sourcing store, AWS lambdas for commands and queries, and ECS for projectors.
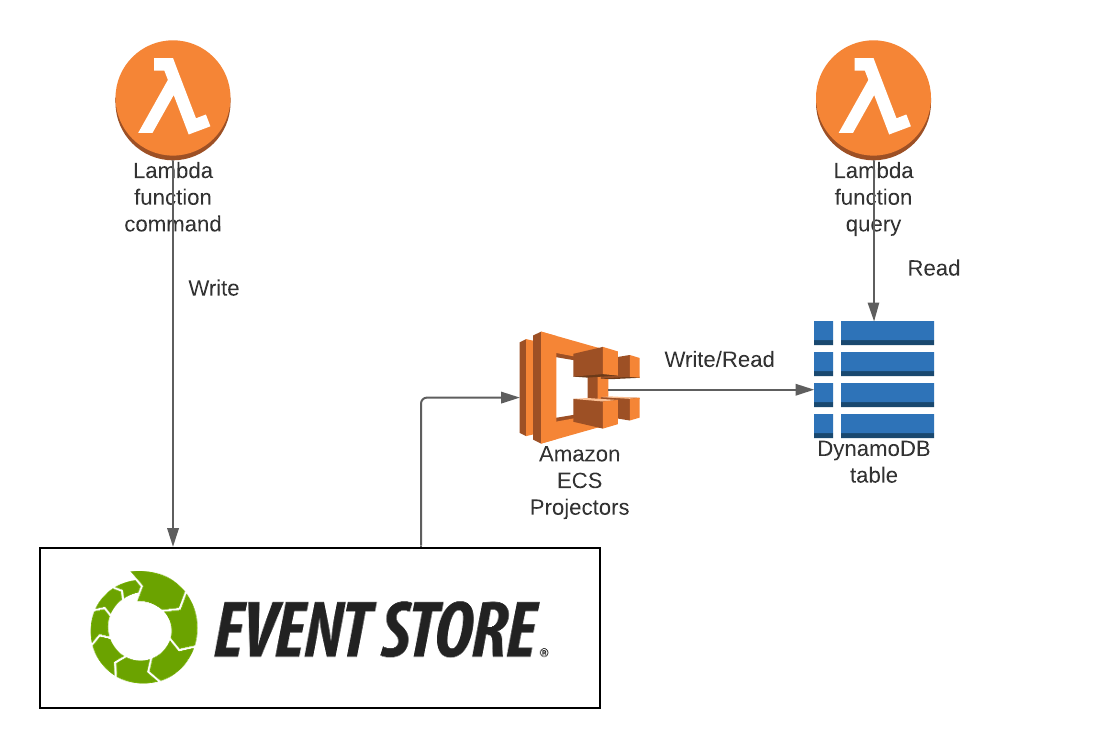
In this architecture, commands will save new events in EventStore. Then Projectors will be listening for those events and they will use projections to create read replicas into any reading efficient storage. In this case DynamoDB will store our read replicas. Finally, queries will use those read replicas from dynamodb to execute read operations in a very efficient way.
This architecture is very efficient and flexible, since the events can be projected into multiples data stores or used for other purposes like creating integration events. However, it brings more complexity than using a single storage with one single REST API which writes/reads. That is the reason why we can find some articles over the Internet blaming Event Sourcing, when the problem might be their lack of experience or knowledge to apply it properly. On the other hand, there is not too much good documentation for advanced scenarios. That is the main reason why I decided to share this post.
Eventual Consistency
The main challenge of Event Sourcing with CQRS is eventual consistency. In CQRS there is eventual consistency between commands and queries. This means that once you committed one command for a particular aggregate, if you query that aggregate, you might not have the latest version. However, occasionally you will have latest version if you keep querying it.
This same effect happens in most of asynchronous, distributed or highly scalable systems, like DynamoDB, ElasticCache, etc.

Something cool about Event Store is the fact that it is strongly consistent at aggregate level. That means that events for a particular aggregate will be consistent, so once you commit one event, if you query that aggregate, you will be able to get latest in a consistent way. Due to this feature, if you need to ensure that you are seeing latest, one option is querying Event Store. However, this query might not be efficient, since you need to read all the sequence of events for that particular aggregate and apply those events in order to get the latest projection of your aggregate. This might be specially inefficient when you have many events to read.
Efficient reading operations for commands validation
Commands need to read aggregates, in order to get the latest status, so it can validate current commands and apply the new ones on top. In order to do so, we could read from EventStore and re-hydrate the aggregate. But, like I mentioned above, this might be not efficient if we have many events to read.
One option to reduce the number of events to read is creating snapshots. For example, from time to time, we could save the current status in EventStore as a snapshot event, so we don’t need to read previous events anymore. This could be a good technique to reduce the number of old events, but it could be not very suitable to do it very often, since it would increase of your data in EventStore and it would require more writing capacity.
However, as we’ve seen previously, in CQRS normally you have a read replica the status of each aggregate that we update each time we process a new event. As we mentioned, that copy might be stale, but most of the time it will have latest. So we could use that copy as snapshot for our queries coming from commands, since that store is highly scalable and optimized for reading operations.
In particular, the proposed architecture looks like this:

So commands well query our read replica store in order to validate commands. In order to make those queries even more efficient (and save RCUs in DynamoDB), a DynamoDB DAX cache has been introduced on top of DynamoDB table. In addition, having a cache on top of DynamoDB table will also improve the performance of reading operations coming from queries and projections, so this is highly recommended. If you are using DynanoDB for storing your read replica, DAX is a really good option, because you won’t have to deal with cache sync, which can be tricky. However, this approach it is also valid for other stores and caching technologies.
Adding strong consistency
But…wait a moment! we said that what we have in our read replica could not be latest, due to eventual consistency. So, what would it happen if we are not using latest to validate our commands? Well, that could be very messy, but luckily, EventStore is strongly consistent. So, if we keep track of the version of the aggregate that we have in DynamoDB, we will be able to know if our data is stale. In order to help with this, EventStore will throw a WrongExpectedVersionException if you are working on stale data (more info here).
So, for example, if we have a snapshot with version number 1000 and EventStoreDB throws a WrongExpectedVersionException telling us that latest version is 1003, that means that we don’t have latest 3 events in our read replica yet. What we can do here is reading those 3 events from EventStoreDB and apply them to our snapshot version 1000, so we would have latest and we can use it to validate our commands.
The flow diagram would be something like this:
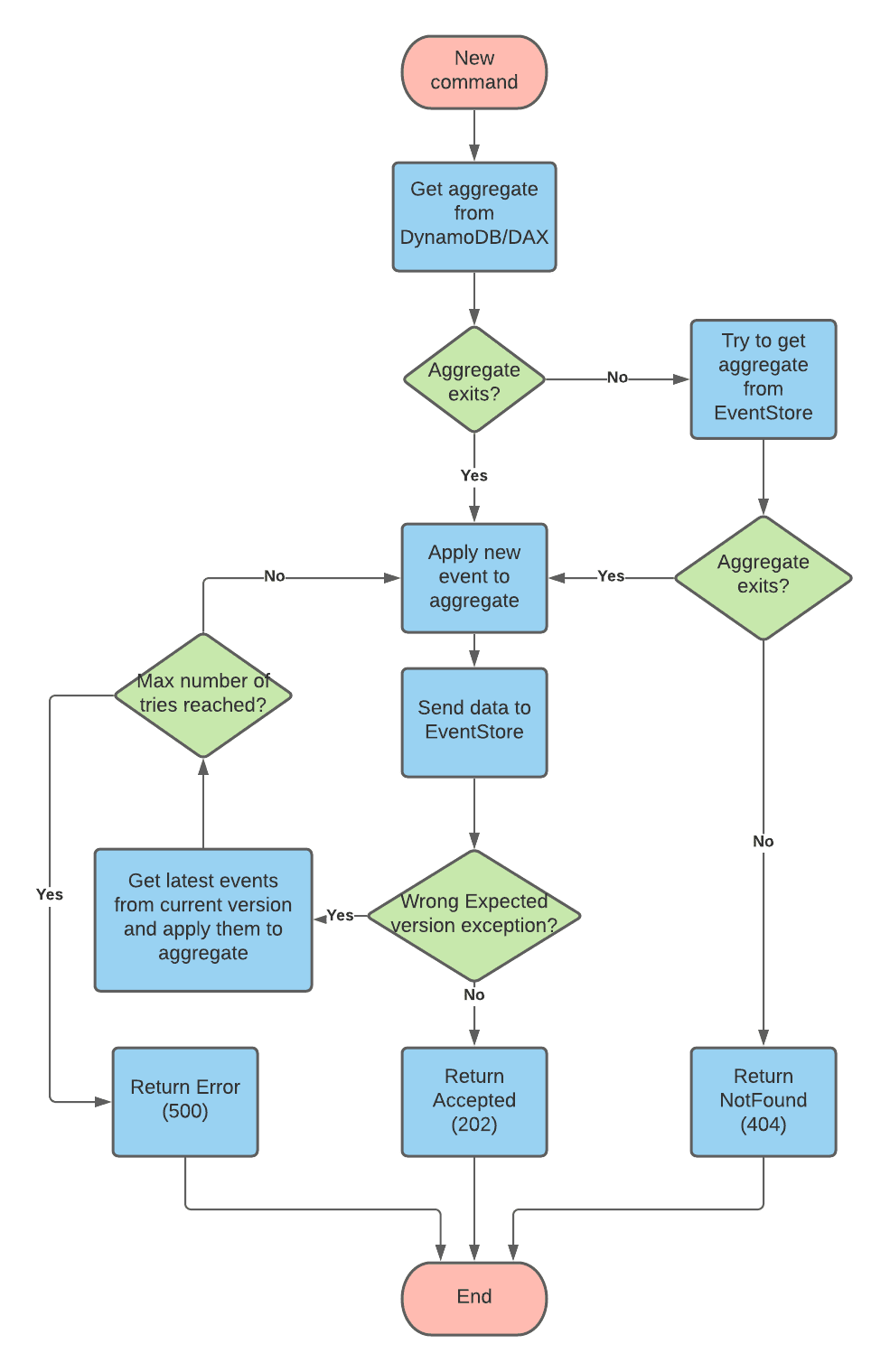
In case we are having updates in parallel, the algorithm will try to catch up for defined a number of times. If we reach that limit, it will throw an exception.
The idea behind this approach could be also used to cover other scenarios, like queries with strong consistency. In the same way DynamoDB allow us to query with strong consistency (more info here), we could specify in our query that we want to ensure strong consistency. In that case, we would use the aggregate version that we have in DynamoDB and then, we would check in EventStoreDB if there are any pending events. If there were any, we could apply them to the aggregate and return it.
Conclusions
In this article we have seen a method to improve commands performance by using our read replica as a repository for snapshots. This prevents having to read the whole sequence of events from EventStore each time we need to query a particular aggregate for commands validation. If we don’t have latest in our snapshot, we just need to add missing events, taking the most of the two stores.
In addition, DAX was added on top of DynamoDB to improve the performance for querying these snapshots. This will improve the overall performance for commands, queries and projections without having to deal with tedious synchronization processes to keep the cache up-to-date.
This technique could be also used querying with strong consistency in our query handlers.